There's no need for me to discuss the obvious utility of this site - if you haven't yet, just go and play. It's immense.
My own playing has led me to some reflections on the field in general and my own experience while I've been slowly learning about digital humanities. Problems remain in that we seem hide-bound by incumbent technologies of understanding and analyzing the data provided by medieval manuscripts. The issues have been capably and entertainingly highlighted by the webcomic XKCD and the following draws on their comics based on some of those problems. Clearly we're not alone.
We can little conceive of the power of the network of users that are interested in our areas and the same is true of our own self-knowledge about what we are capable of doing in this sea of activity, leading to the situation Matthew Fisher outlines.
Humanities scholarship has always been crowd-sourced. Using facsimiles, critical editions, and our own notes, we place-shift and time-shift. Through direct collaboration we analyze enormous corpora in granular detail, effectively allocating and distributing tasks. Simply by working on the same texts and topics as others do, we engage in complex forms of indirect collaboration, bringing together heterogeneous datasets and skillsets. We are the buzzwords we've been waiting for.
Matthew Fisher, 'Authority, Interoperability, and Digital Medieval Scholarship' Literature Compass 9/12 (2012)
The result of the mass democratization of access to semi-primary materials, secondary analysis and data has led in the main to a lot of increasingly granular analysis, awaiting, presumably, the great unifying leap that will take all data and bring it together.
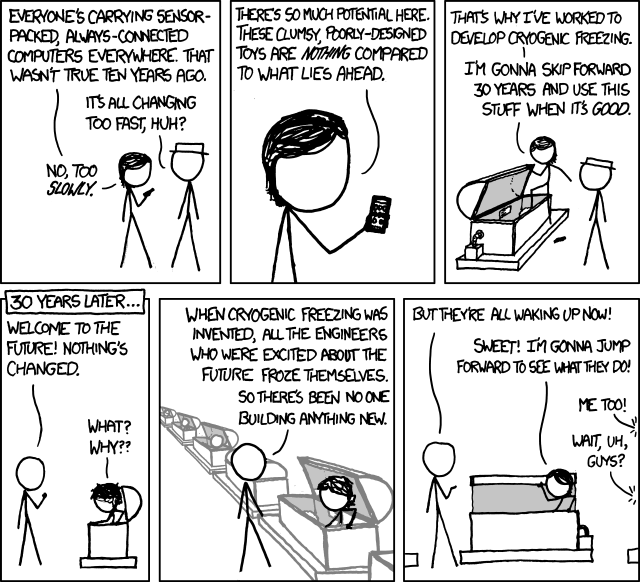
In order to take action there seems to be a general feeling that we must have more knowledge of what it is that we are doing from a technical aspect.
The result is fairly predictable. Things take time in academia and I am sure that this idea was tried before on various scales with various focuses but the technical obstacles are HUGE. Quite apart from this, if you've ever tried to show a parent or grandparent something on your internet enabled mobile device and asked them to navigate it in any way, shape or form, you will be aware of how difficult it is to catch up if one allows oneself to be left behind by technology.
There are some notable exceptions. This is not an exhaustive list but the Dictionary of Old English Corpus, Fontes Anglo-Saxonici and International Medieval Bibliography have all gone some way towards addressing this issue. Manuscripts Online, it is hoped, will provide the next leap in this direction.
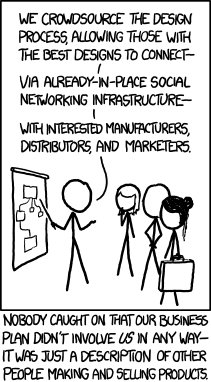
Quite apart from such vulgar considerations, there are still many positions voiced in the community that this kind of endeavour is not only unweildy but uncompletable. Indeed, there is sympathy for this view in the sense that the Herculean task ahead of any scholars trying to unify not only databases built on different systems but different forms of data management and visualisation into a single place is incredibly daunting and, to many, uninteresting.
Generalising the rule from one to many is incredibly difficult. When faced, for example, with a chunk of prose that looks interesting or suspicious to a given scholar, the choices suddenly abound: shall I do an OE Corpus search to see where else it comes up? Once I've identified the texts in which it appears I can check out Fontes and find out if it drawing on any of the sources in other languages that it draws on. I could dig out the EETS edition and sort through the front matter to find what the (current) view on the origins of this section are, or where it links to the rest of the corpus or culture. I could go to IMB and find out if there's anything of interest there, or perhaps HALOGEN/ESawyer/PASE or any number of more specialist resources depending on the nature of the source.

The thing is that I can do all of those things in the space of perhaps an hour or two. The material at the end of such a search would be disparate, connected only through the nodes of my head and my memory of the 'research journey' I have taken to get there, and of course, by the hints and tips of my colleagues and supervisors whom I will have inevitably bumped into on the way to the library/get a coffee in the mean time.
It would not take the months (years) of work to make all that available in a union search portal. Plus, I now have a coffee.
With this stack of photocopies, written and typed notes and scrawls in word documents on my hard-drive in front of me, I don't know how one would display the entirety of that dataset visually on a single page. I'm not looking at a mono-layered, linear dataset but one that is riddled with interconnections and intraconnections, vertical and horizontal, temporal, interdisciplinary and entirely unwieldy.

This type of scholarship is still impossible to replace - its beautiful simplicity and astounding functionality is only reiterated by such game-changing projects as Helmut Gneuss' Handlist which takes the tradition of Ker and Sawyer to new heights of completeness and utility. Similarly, the Early English Manuscripts Project, Parker on the Web, Turning over a new leaf and Manuscripts of the West Midlands Catalogue show the next steps in this style of research, especially in terms of hybridity.

In their construction, however, all of these projects have met difficulties in terms of cataloguing (looking forward to the Leiden project's way of dealing with this!): how does one refer to, for example, Ælfric's Catholic Homily from the first series on the Decollation of St John the Baptist? Is it perhaps as I have just described it, as Clemoes' Homily 35, as Cameron Number B1.1.36 or as Thorpe puts it, 'Decollatio S. Johannis Baptistæ' or indeed his Homily 34, or as in my research, Gneuss G.14.2.1.1.36, or as my database refers to it, the singularly uninspiring: 3000059?
The same could be argued for interfaces. A quick survey of the websites I have been citing shows many different platforms. Whereas EEMS is html generated from xml pages with indexes and searches generated from Python scripts and a basic google search of the domain, DOE corpus operates on a similar principle but with more dynamic searching, and Parker on the Web adds the intricacies of Lucene to enable its search tool, Fontes looks to be a PHP and MySQL query affair. At least the trend is clear...
Web-based solutions are the only feasible answer in the digital age. The CD has died and that kind of media more generally is on the way out. As everyone seems increasingly linked to their personal cloud, however, they make that operate, the conversation has moved away from static to dynamic.
The data can be further subdivided into relative levels of certainty and reliability. In the former, the Humanities has a long way to go before it catches up with other disciplines, but in the second we have ample experience, not least through marking essays reliant on resources of suspect credibility. Which leads to an even less desirable situation...

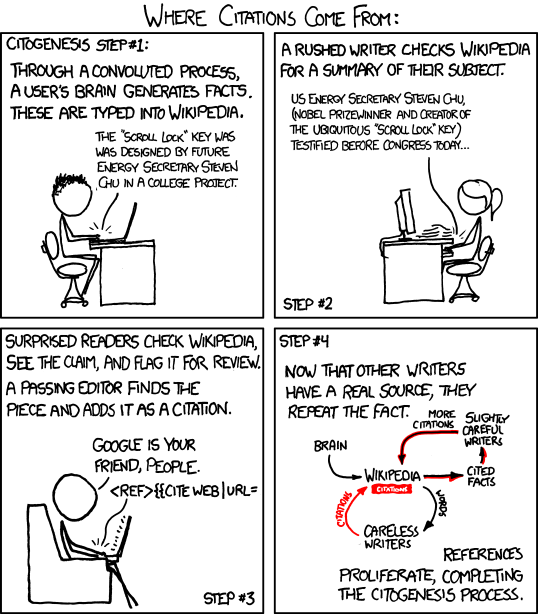
All of this is by way of saying both "WOW!" and "Well done!" to the MSSO team. The rest of this post is really about some of my thoughts on what happens next.
This problem of having a mass of data that is entirely unmanageable has been faced by other fields for years. The one that springs to mind for me is Economics, where uncontextualised statistics abound (especially in the media) and teaching methodologies have had to run to stand still, let alone keep up with the visual-centric world in which we live. By contrast, we literary scholars (and Medieval Historians seem little better in this regard) impose on the past a logo-centric view, eloquently illustrated by the very nature of the research question I mentioned in my example.
The way Economics has dealt with this is by tackling the issue on multiple fronts. Firstly, in an Economics undergraduate course, you do not simply study the great works of great economists past, nor do you abuse their insights as windows on the world they perceived, rather you start with a mathematical focus so that the budding economist can ask intelligent questions of the data with which they are presented. Next students learn about the way in which modelling works and doesn't work in the context of questions observing a world on which we have only a partial view, analogous to our inquisition of critical theory in literature, or historiography in history. By the middle of their second year they will have an understanding of the the statistical methods needed to test even the most basic of economic models.
Teaching has had to move on apace not only to engage students but to debunk popularly held myths about the world. Hans Rosling is at the cutting edge of this. In order to understand data we must first visualize it so we can ask intelligent questions of its properties.
What bearing does this have on Medieval studies? Well, it possibly helps to answer my question of how one would go about showing the data from a general search of 'medieval resources'. As an example consider the following:
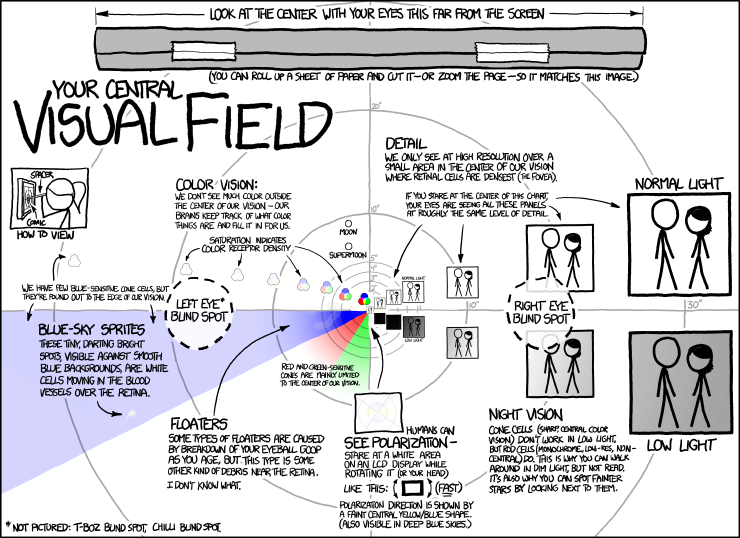
How do we populate this with our search results? Well things that we are able to focus on represent those things closest and most linearly connected to the query in hand, and as one gets further away one could consider more oblique links. An excellent example of how this could be not only populated with metadata but also designed to make the interface replicate connections is CDragon (the engine that makes Bing maps so quick) and Photosynth (available as an app for creating panoramas from camera phones) illustrated by Blaise Agueara y Arcas at another TED talk. Prototype screenshots from the DigiPal team look promising in this regard, but the step is evolutionary, not revolutionary.
So what's my point? As I've been working on this over the last few months, what comes up again and again is that it is impossible to satisfactorily display results in searches on humanities topics. I'm looking forward to seeing how interfaces change over the next couple of years as key projects reach maturity, but for the time being it's back to excel to see if I can make sense of Wulfstan.
Owen Roberson 16/04/2012
This is true, though, the databases are more than JUST intertwined networks leading into each-other - therein we find progress - and I say thank goodness we can make use of our encyclopaedic knowledge for something - at least we are still of use ;)
ReplyDelete(love the comics :)
ReplyDelete